
openclaw的一些使用感受
Openclaw的一些使用感受
从之前分享如何安装openclaw刚好过去一个月了。这段时间使用的也比较频繁,已经把它从一个刚安装的空白系统,调教成了能帮我推新闻、写文章、写代码的私人助理团队了,这次分享一些使用的感受。
openclaw 分工
openclaw有着多Agent独立分工的机制,用来分工。我创建了三个专属Agent
- Mickey(管家):主助手,管日常问题、定时任务、所有Agent的调度
- Jack(码农):专属代码助手,负责写脚本、改bug、调试功能,所有开发类需求,自己会记项目配置、踩坑记录
- Rose(写手):专属写作助手,我把之前写的小说、文案都喂给了她,模仿自己风格写作
每个Agent的记忆完全隔离,Jack不会知道我给Rose喂了什么小说素材,Rose也不会知道我让Jack写了什么脚本,用久了它们真的越来越懂你的习惯,不用每次都重复说要求
实现的功能
- 每日财经新闻自动推送
这是我最早做的功能,前前后后改了三四版:
- 最初版:调用大模型联网搜索生成,但是模型生成的感觉有点生硬,还得要配置支持联网搜索的模型才行
- 第二版:改成直接爬财联社公开接口,不用调用模型,纯shell脚本处理,但是效果不太好
- 最终版:直接浏览器检索,然后加了自动过滤、内容校验,自动筛掉个股涨跌、牛散持仓这类没用的内容,只留宏观政策、产业大事件。

- 小说创作续写
因为我平时喜欢写点小说和随笔,喂给了一些之前写过的稿子给它,然后让它续写。她直接顺着我的文风续写,写完直接生成对应文件存到我指定的文件夹里。
后面的确在相应文件夹中生成了文件
- 开发任务
工作上会有一些开发工作也用到了,写什么脚本、处理什么数据,直接跟Jack说需求,他直接写好还帮我测试,比如财经新闻爬取脚本,前前后后改了好几次数据源、过滤规则。目前用的比较多,简单举几个例子。
比如这个格式转换的脚本:
因为音乐歌词是在windows下载的,但是我平台又部署在linux上,所以需要转换一下格式。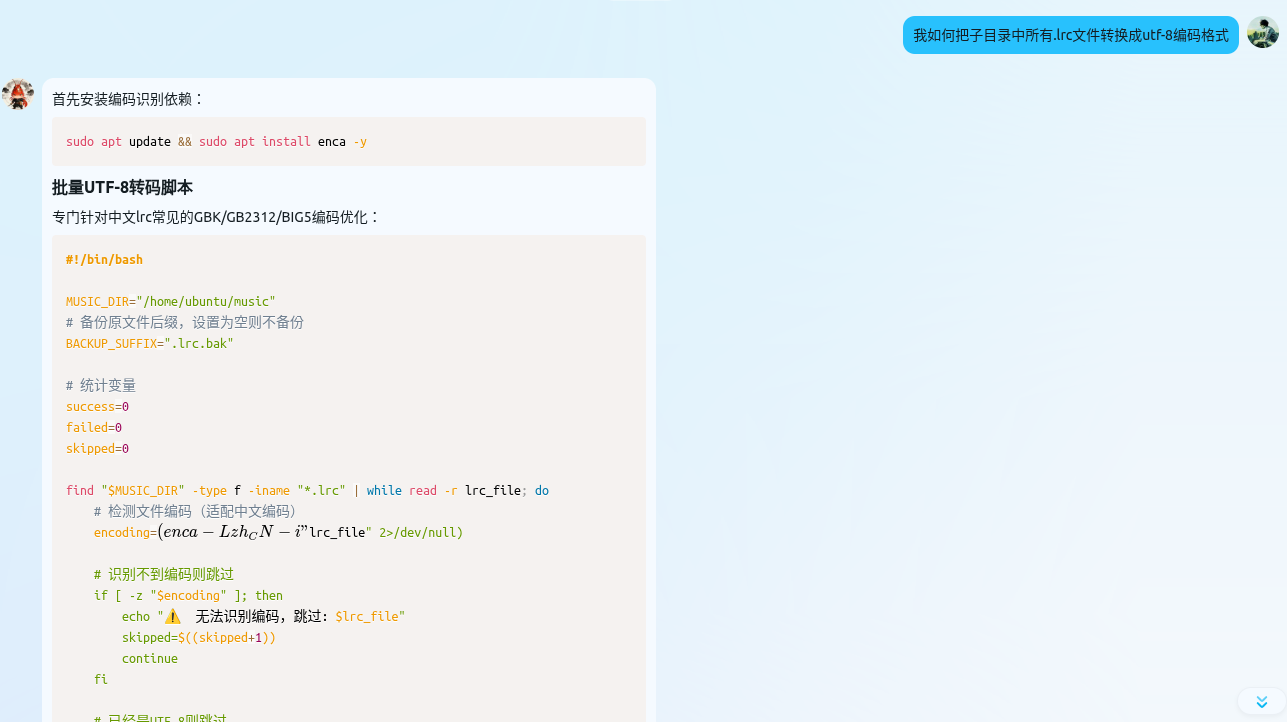
数据手册快速阅读定位:
这个对嵌入式开发工作者太实用了,不要花费太多时间去了解寄存器了。
按我需求写的记账小程序:
仅截取部分功能,主要功能可以导出和录入帐单,以及收支显示,并且可以自定义的账单分类。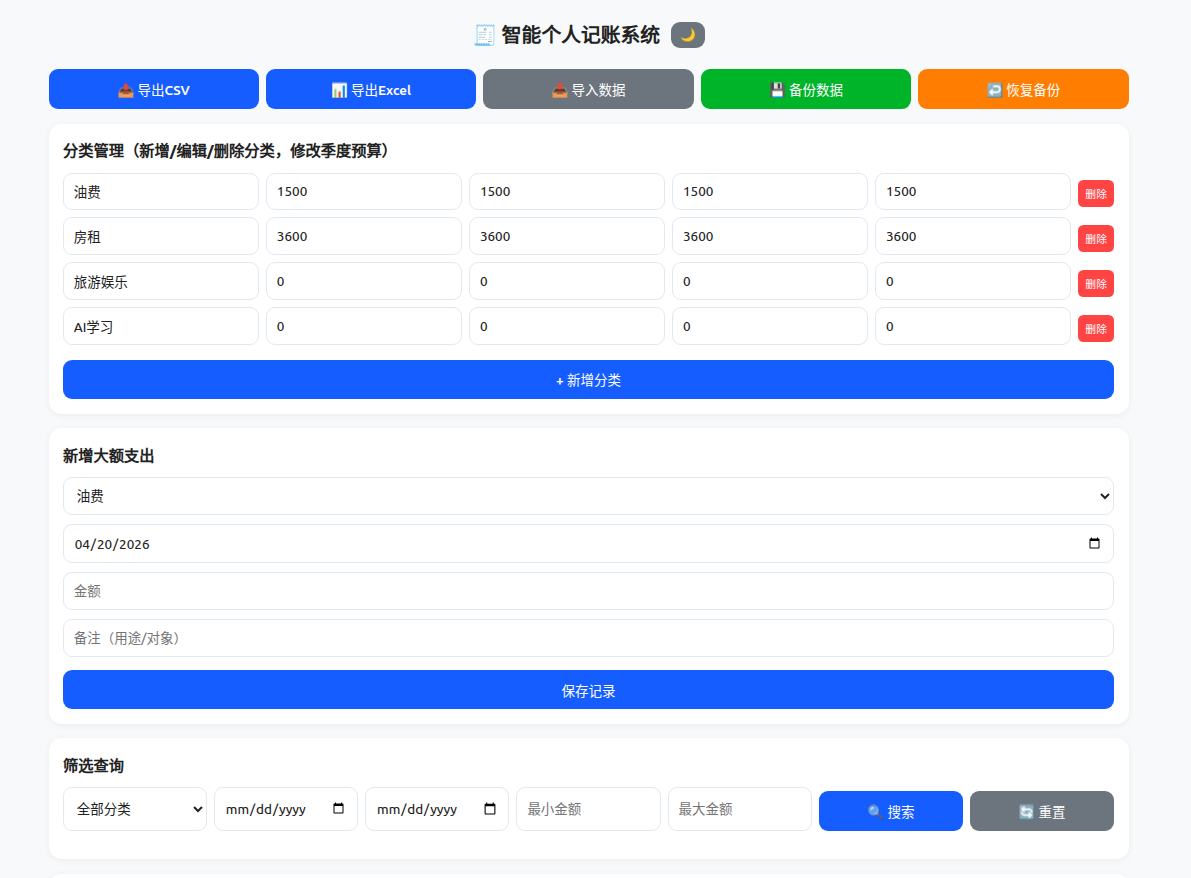
openclaw底层
我经常使用终端,会查看openclaw生成了哪些文件,发现OpenClaw的记忆机制非常简单。
1 | # 全局主配置(最重要) |
然后也大概了解了下,其实它百分之九十以上的技能都是记忆技能,少部分的是开发者开发的脚本或者调用API获取的技能,功能型Skill很少,并且能够找到替代。这样会导致后续tokens请求会变很多,久而久之就是记忆垃圾场。目前我是买了火山和阿里的coding plan。包月还对模型用量感觉不明显。
优点也比较明显,完全本地化!所有数据都存在你自己的机器上,不用担心聊天记录、写的稿子、项目信息泄露,想接什么模型就接什么模型,完全不受制于平台。
总结
Openclaw 需要自己调教,要真正成为私人AI助理,还需要很长时间,自己需要有一定耐心和技术基础。经常需要自己升级和解决崩溃问题。
最后,如果你喜欢折腾,想要一个完全属于自己的AI助手,自己可以试试。





