
Linux系统--ocr工具使用
Linux系统中OCR工具
我们时常会遇到一些扫描见或者影印版的pdf,它们无法搜索、无法复制,就让人很困恼。本文介绍在Ubuntu/Debian 环境下,两种从PDF中提取文字的实用方案。分别是自带Tesseract原生方案和开源项目 “OCRmyPDF”。希望对你有所帮助。
Tesseract 方案
目前大部分OCR,底层都依赖Google开源的 [Tesseract OCR],
安装
1 | # Ubuntu/Debian |
验证
1 | tesseract --list-langs |
使用
我们大多时候都是仅仅只需要纯文本用来写文档啥的,不需要保留PDF排版或者索引。一般步骤是“PDF 转图 → OCR 识图 → 合并文本”。参考步骤如下:
1、高清PDF转png 300dpi
1 |
|
效果如图:
打开图片,感觉内容识别效果还可以,但是英文识别效果一般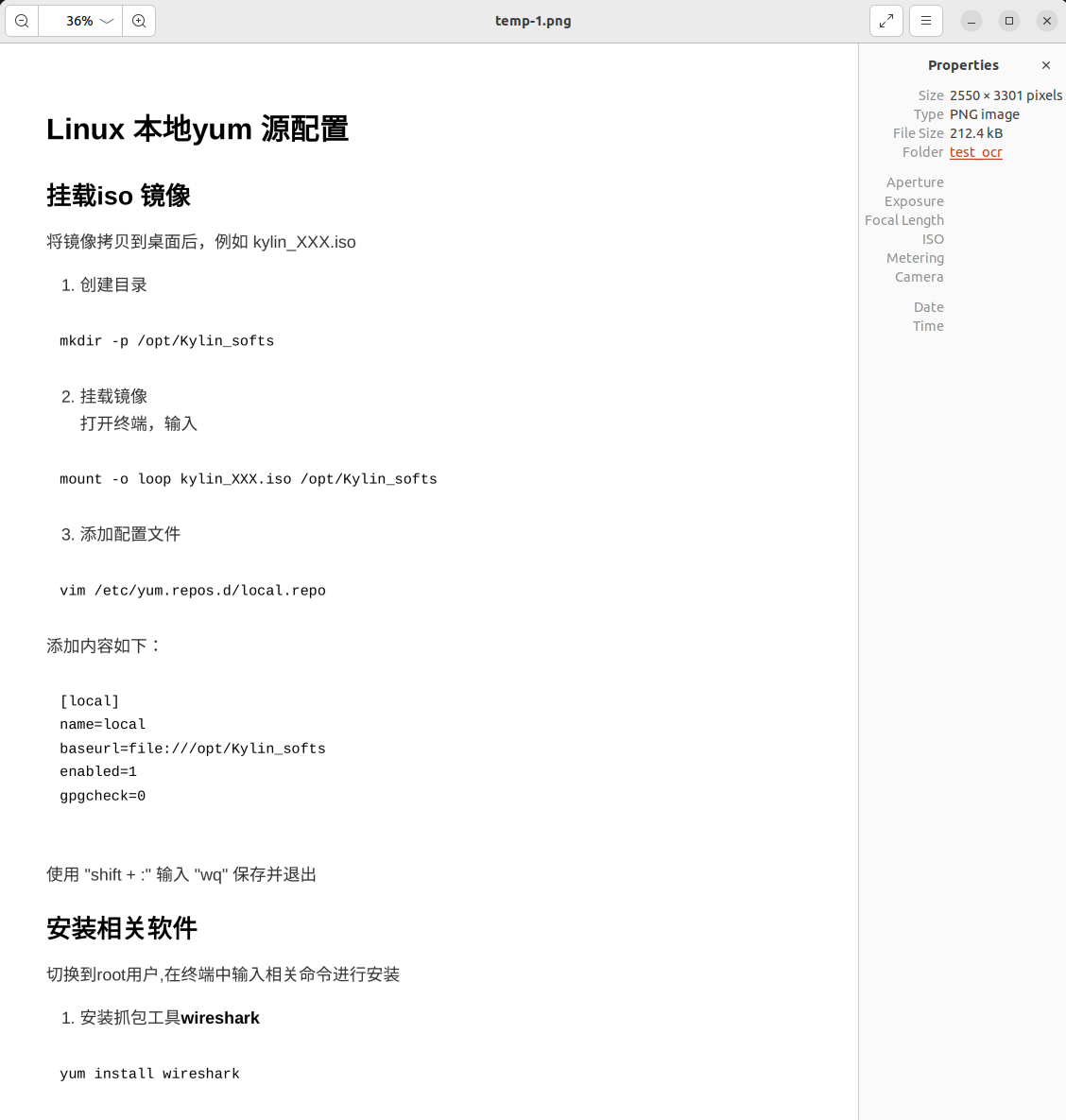
2、中文+英文OCR,合并文本
1 | for f in temp-*.png; do |
参数说明:-l chi_sim+eng:同时加载简体中文与英文训练数据,这是避免乱码的核心。--oem 3:使用默认神经网络引擎stdout:直接输出到终端,方便管道重定向。
输出结果保存在output.txt中,可以看到还是有些许的乱码。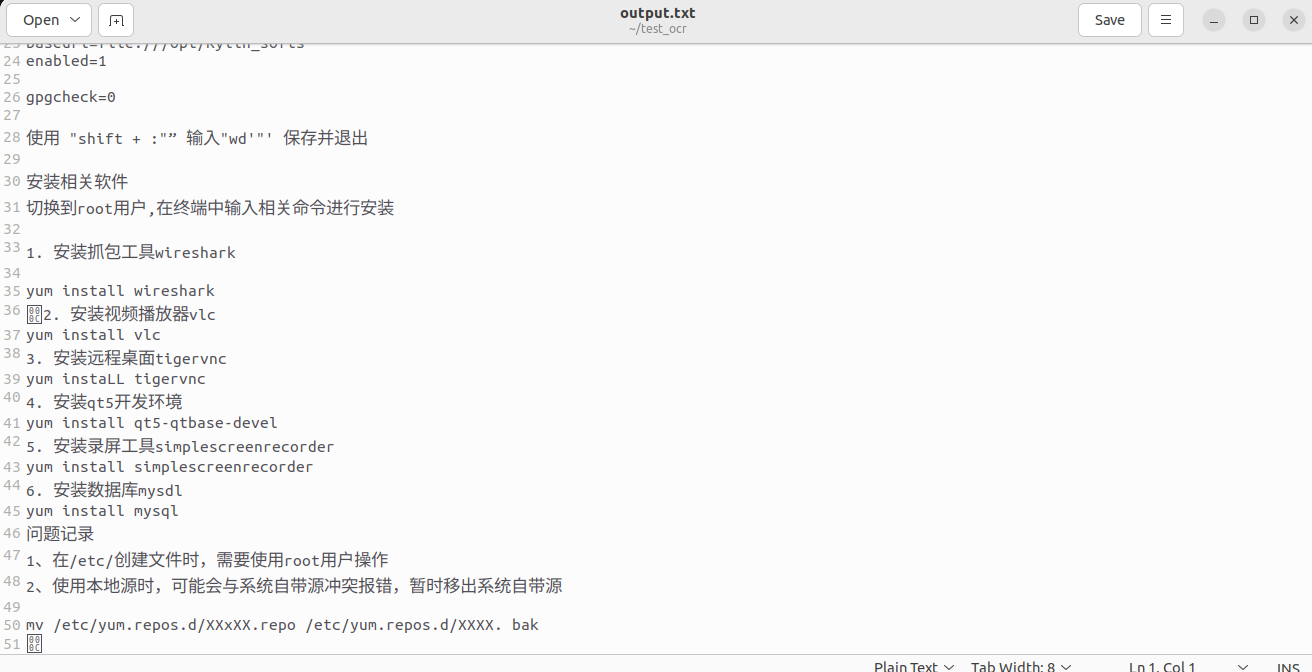
虽说如此,但文字算是不要自己再敲了,拿过来直接写方案,也很方便。
3、清理临时图片(可选)
1 | rm -f temp-*.png |
OCRmyPDF
OCRmyPDF 是基于 Tesseract 的封装工具,它会在 PDF 的扫描图像背后附加一层隐形文字层,使文件外观完全不变,但支持复制、搜索与索引。它还能自动完成图像预处理、PDF/A 归档转换、元数据写入等任务。
开源项目地址:ocrmypdf
安装
1 | sudo apt install ocrmypdf |
使用
1、生成可搜索 PDF(推荐,不乱码、可复制搜索)
1 | ocrmypdf "test.pdf" "test_OCR.pdf" |
处理中文文档时必须指定语言:
1 | ocrmypdf \ |
2、只处理扫描页,保留原有文字页
1 | ocrmypdf \ |
3、全部OCR处理
1 | ocrmypdf \ |
参数解释:
| 参数 | 作用 | 适用场景 |
|---|---|---|
-l chi_sim+eng |
指定 OCR 语言(Tesseract 语言代码) | 中文文档防乱码必加 |
--deskew |
自动纠正页面倾斜(±约 15°) | 扫描件未放正 |
--clean |
使用 unpaper 清理扫描黑点、噪点、边框污渍,仅用于 OCR 识别,不写入最终 PDF | 老旧/低质量扫描件 |
--clean-final |
同上,但将清理后的图像写入最终 PDF | 需要视觉降噪输出 |
--rotate-pages |
根据文字方向自动旋转页面 | 扫描方向混乱(横竖颠倒) |
--remove-background |
去除灰度/彩色背景,统一为纯白 | 报纸、杂志扫描件 |
--output-type pdf |
输出普通 PDF(默认输出 PDF/A 归档格式) | 需保留 JavaScript/多媒体等 PDF/A 不支持的特性 |
--output-type pdfa |
输出 PDF/A-2b 长期归档格式 | 档案数字化 |
--sidecar output.txt |
额外输出一份纯文本文件 | 需要同时提取文本做全文检索 |
--force-ocr |
强制对所有页面进行 OCR,即使已有文字层 | 原 PDF 文字层损坏或乱码 |
--skip-text |
跳过已有文字层的页面,仅处理纯图像页 | 混合文档(部分可搜索、部分扫描件) |
--redo-ocr |
对已有文字层的页面重新 OCR,保留原图像 | 旧 OCR 质量差,需要升级 |
--optimize 3 |
最大级别图像压缩(JBIG2/无损),显著减小体积 | 档案存储、网络传输 |
-j 4 / --jobs 4 |
启用 4 并行 worker 处理多页 | 多核服务器/大批量任务 |
--image-dpi 300 |
为缺少 DPI 元数据的图像强制指定 300 DPI | 截图或异常 PDF |
后语
如果只需要纯文本做后续分析,使用原生方案足够了,如果需要保留原始排版、生成可搜索文档、构建数字档案,OCRmyPDF(方案二)是工业级选择。它把”转图→预处理→OCR→压层→优化→输出”整条链路封装在一条命令里,极大降低了流水线维护成本。








